👋 Hi Again, Forgiving Failure, & Loops in DAGs
Sanity Check • No. 011

Hey y’all,
It’s been a while! A few things have changed since you last heard from me. Here’s what’s new:
🦣 I changed jobs. A year ago, I left my internal analytics role for a consulting role with Mammoth Growth. The goal has been to do the same work for more companies.
🧪 I’m experimenting with work in public. A YouTube video discussing data platform migrations, Twitter (X?) threads about the dangers of floats, and this newsletter.
👶🏻 I had a baby! She’s a beautiful, healthy five-month-old. I couldn’t be more pumped to be a dad and be able to unleash all my dad jokes.

PERCOLATING PONDERINGS
🚧 Caution: opinions still settling, and I’d love to hear yours
Test Forgiveness
Mistakes happen. Tests catch them before the mistake becomes someone else’s problem. But now that you’re aware of the issue, what do you do?
Allow the error through to keep processes and dashboards running on time?
Author a patch PR to band-aid the pipeline quickly?
Demand that this issue is not your responsibility and it can only be fixed in the source system… someday?
Each of these responses comes with tradeoffs.
Timeliness vs Correctness
Ownership vs Stewardship
Priority vs Policy
I’ll leave balancing these scales up to you. I can help buy you the time to find that equilibrium… with Test Forgiveness!
Test Forgiveness doesn’t hold your reports hostage until every demand is met, but it does alert the team to get started on a fix.
Test Forgiveness won’t hold a grudge. It can even accept the flaws that make a dataset unique.
It can all be implemented in three simple steps:
Give yourself some slack. Instead of erroring on the first mistake, allow a handful of questionable points to slide. Use the `warn_after` and `error_after` settings in dbt (docs).
Set a timebox. If the data issue is not addressed within that time, then it was not that much of an issue! The `where` dbt test config is helpful here (docs).
Keep a record of exceptions. Sometimes suspicious data points are actual data points. Give these cases a free pass and jot down the reason in a note to your future self. The dbt project evaluator package sets a good example for this workflow (docs).
And with that, it’s time to forgive and forget about the small test failures holding your pipeline back.
I forgive you mega-deal that sold above list price.
I haven’t forgotten you, fluttering heartbeat event of May. I have merely moved on.
How do you handle test failures? Or you could just take Pedram’s advice.

—
Human-in-the-DAG
People have opinions on how the data should be classified. Imagine a product manager wanting to claim a new `item_id` for their fiefdom. As data engineers, how do we include their thoughts without becoming a bottleneck?
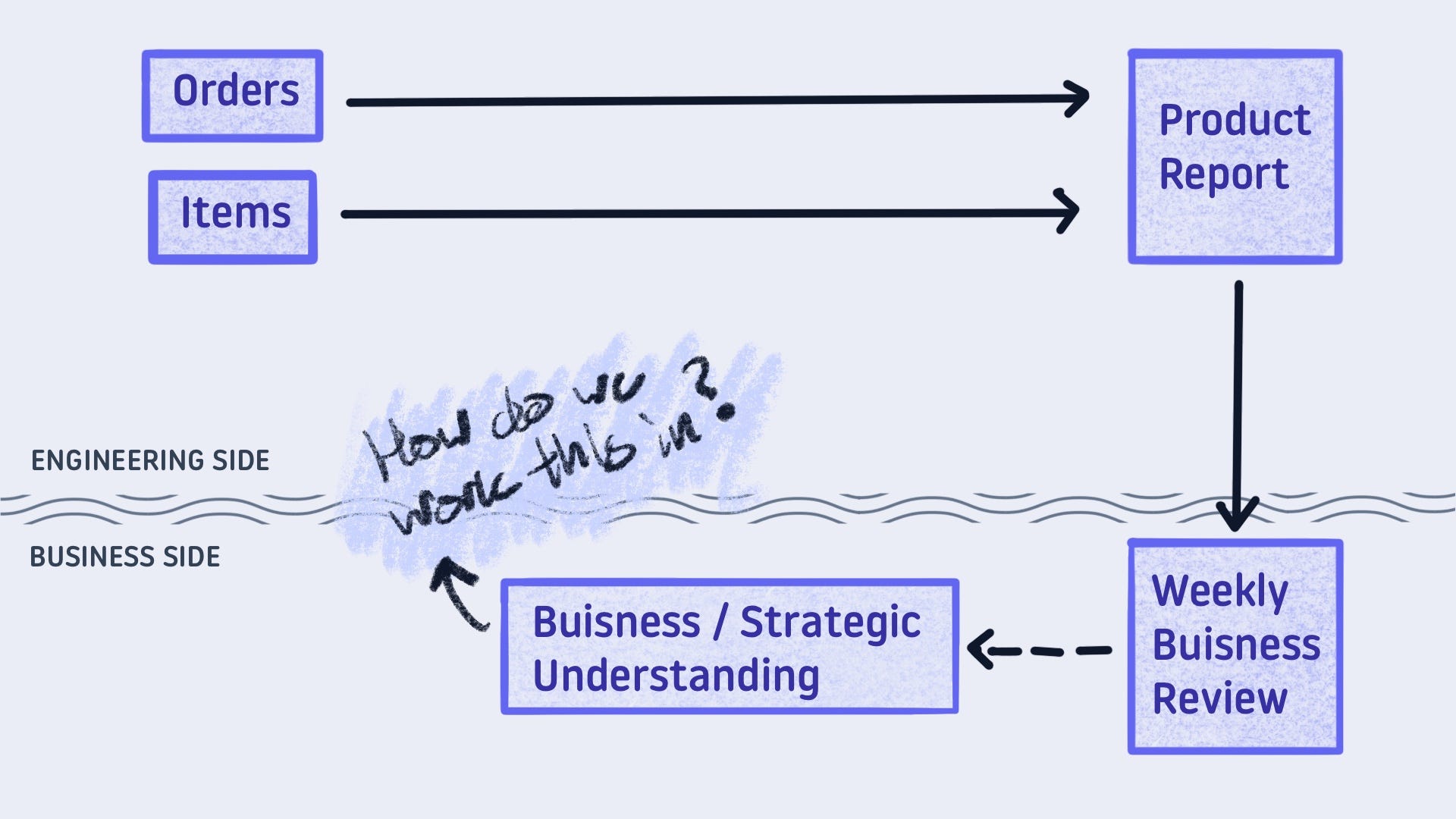
Level 1 - Verbal Reqs & Seed File
The quick fix is to introduce a seed file. Gather the requirements, create a mapping in a csv, and paste it onto the source data on the way to the report.

While this works, it leaves the team exposed to a constant stream of changes. The business understanding will change, and each change means new work. It’s not the work we enjoy as data practitioners. We can do better.
Level 2 - Read from a Shared Doc
The business user knows what the categories should be. They were just dictating the requirements! Why not let them input the categorizations themselves?
That is possible. Coordinate a shared spot, say a Google Sheet. They provide the mapping, and you blend it into the pipeline. No one’s flow is interrupted… until it is.
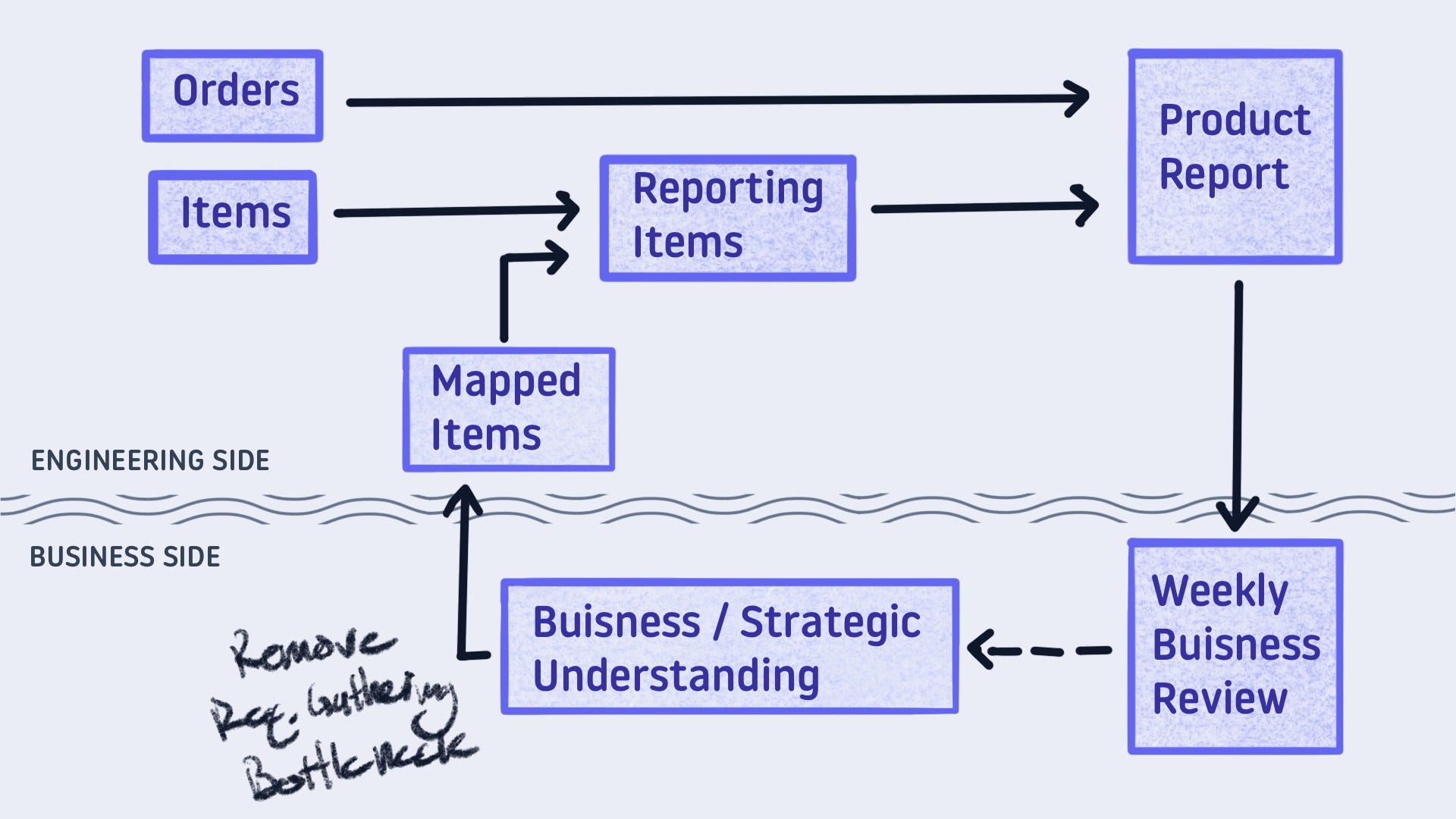
With the unparalleled freedom of a spreadsheet, your stakeholder will add their own flair. It may be a new category that triggers an accepted values test failure. It may be a reformatting of the table that causes the refresh to break. The point is without more guardrails this workflow will break.
Level 3 - Read and Write to a Shared Doc
To give our colleagues better context, we need to be able to read from and write to the shared document. We write in data points that need attention. Then read out the updated mapping.
Unfortunately, this external loop is difficult to set up. Using the modern data stack, you would need one Fivetran connector, one Hightouch sync, and a minimum of three dbt models. Due to the heavy lift, this pattern is rarely put into practice.
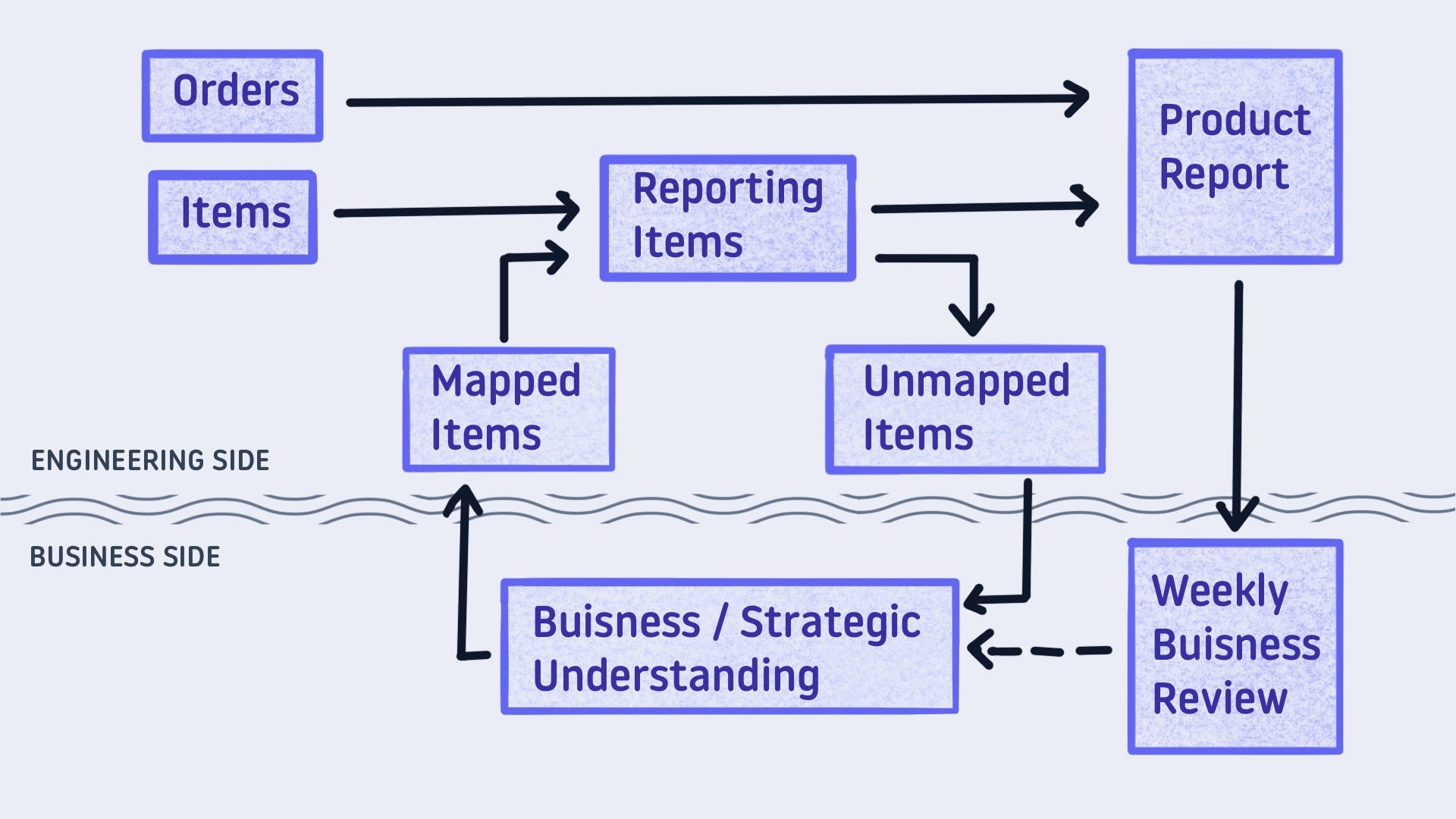
I do believe this last option is an ideal state. Some products roll this out as a feature.
Sigma input tables are excellent
Hex writeback cells can be pushed into service
But I’d prefer something not so tied to a vendor. Possibly a Snowflake native app or leveraging dbt-duckdb external materializations. Definitely something I plan to hack on 👨🏻💻
How do you handle categorical mappings where the knowledge lives with the business users?
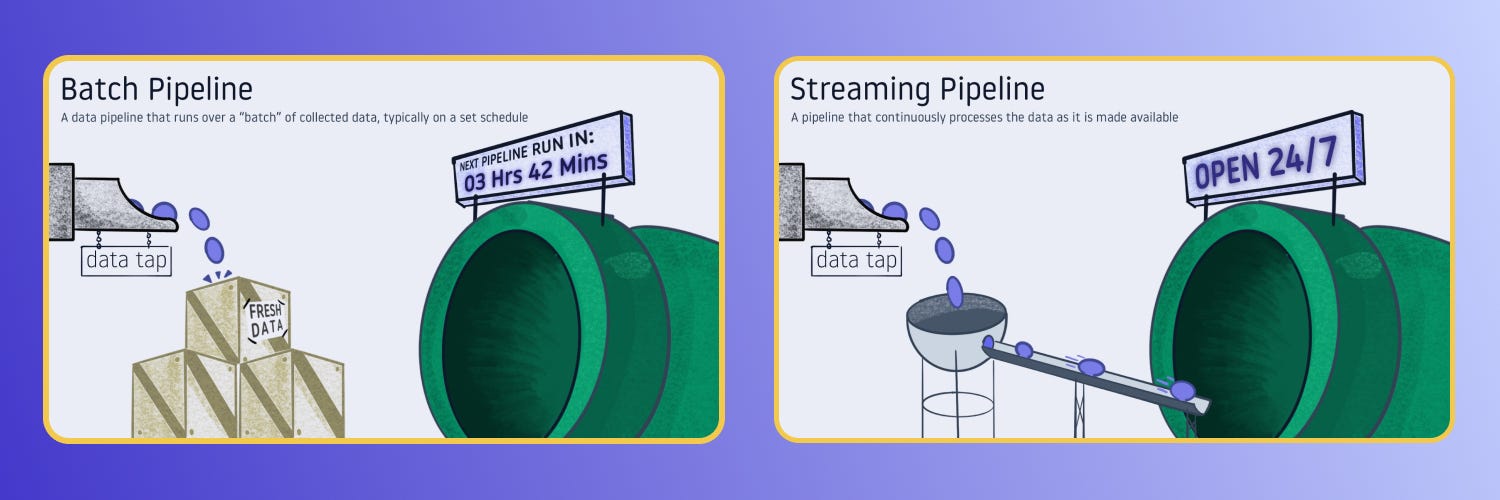
DATA DOODLES
Documenting analytics jargon, visually