

DPIM Framework: Bundling Better Infra, People, Models, and Data


I cannot stop thinking about this tweet.
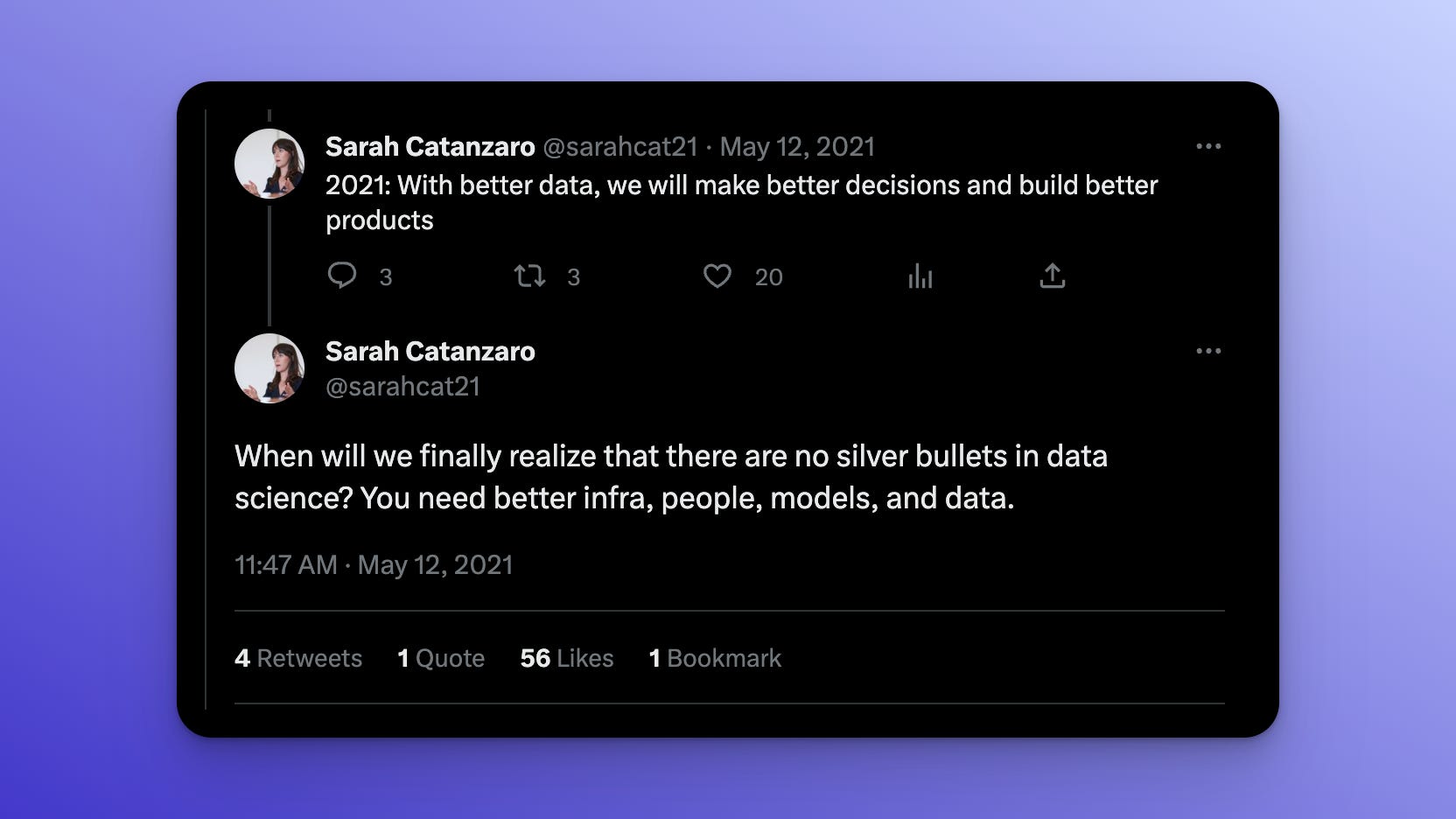
It has been tumbling around the back of my head for months. Sarah’s comment rings true. Your analytics capabilities are capped by the weakest link between your infrastructure, people, models, and data - but what does it mean to have better models? Better people?
I don’t have the answer for you. You’ll need to do the work to find your own better.
But wait!
I can offer a framework to think through what better looks like in your situation. Consider it a recipe just waiting for you to make it your own.
Framing how the four major components of analytics come together to create better analysis is a broad problem. I’ve done my best to simplify, but it is still a complicated view. We are going to ease into it by building up one layer at a time. If you stick through to the end, my hope is that you’ll gain clarity about how your team is delivering value today and identify opportunities to make it even better.
Groundwork
We will use the components Sarah laid out, but let’s change the order and lock in our definitions first.
Data - To some extent, it’s all data from beginning to end. For this framework, think of data as sources - the initial round of input to build analytic value.
People - Analytics is a team sport. Many people are involved in delivering results. I’ll doodle with broad strokes, and you’ll tighten the definition to fit your org. Our main actors are Data Professionals, the teams providing the data, and the stakeholders that receive the models.
Infrastructure - Infrastructure is one of the industry’s favorite topics. It’s simply the tools we use to get the job done. They need not be complicated, but the choice in infrastructure will impact the type of models that can be delivered.
Models - Models can mean so many things in data. Here we will define models as the final data product that data professionals deliver.
With our definitions set, we are ready to layer on our first transparency - like a ‘99 schoolroom.

Let’s begin with the end in mind. Our modeled data is the main asset the analytics team produces. There are a few different ways we can deliver that asset.

Operational Analytics
In operational analytics, we push data back into our business systems. This allows us to embed attributes in the places our front-stage colleagues work day-in-day-out.
This work can be highly impactful for the organization because of the direct route to business processes. That impact comes with greater responsibility too. For Operational Analytics to succeed, it requires accuracy and timeliness at a fine level of detail.
Business Analytics
Think of Business Analytics as traditional BI. Aggregated metrics are sliced and diced in dashboards. Dashboards provide visibility into company performance for leaders. If a metric is trending towards a danger zone, you’re able to double-click into the details to uncover the cause.
Business Analytics is valuable for the peace of mind it provides the company. Seeing that the KPIs are on track frees the business to focus on new products, distribution channels, or other opportunities to unlock the next level of growth.
Strategic Analytics
If a dashboard double-click does not get to an answer, you’ll likely get a message from someone looking for ad-hoc analysis. These are generally more open-ended questions. It’s unclear where the truth will show up, so you’ll be whipping up an analysis like an Iron Chef competitor.
Since strategic analyses have an open-ended question and unclear answer, there is an aspect of sales - of persuasion - needed to deliver an impact. If successful in changing a leader’s mind, this can set the company in a new direction.
Data
Now we have the picture of where we want to go and why each destination is valuable. Next, we should understand the raw materials to be molded to those destinations. The data to be modeled.

Source Systems
Companies rely on a suite of SaaS vendors to run their operations. CRM, ESP, CPQ, IaaS, PLM, CX, and on, and on. The good news - these systems are untouched and the ground truth for the teams that work in them. The bad news - the individual source systems rarely communicate well with each other. The unclear connections between systems emphasize the need for transformation by the analysts. In my opinion, source systems are the ideal place to begin pulling data into your analysis. It’s the only way to provide complete data lineage.
Reporting Systems
Sometimes access to the raw source system is not possible, but there is still hope to get data out of a reporting system. It could be that a vendor only supports report exports instead of a full API to extract granular data. Perhaps some friends in Engineering have already pulled together a suite of metrics into a different database. These reporting systems pre-shape the data, which saves analysts time in the exploratory/metric-defining phase. The trade-off comes from the loss of business context and not having a full view of data lineage. Overall, reporting systems are still a great place to pull data reliably.
Business Data
No matter how many systems a company has, there is always tribal knowledge that lives outside any system or database. Here we are calling it Business Data. Business Data creeps into analyses through spreadsheets of custom lookup tables. Incorporating this knowledge is essential, but be careful if you need to rely on it long-term. Consider having a plan to keep it up to date and determine the controls required to update the data.
Unstaged Data
All the previous data sources were known knowns. They are observable and available to be analyzed. Unstaged data is an unknown unknown. Analysts are unaware of this type of data, and it may contain necessary context. The goal here is to find them - turning them into a known unknown - and create a plan for accessing the data as one of the three other data types.
People
With our starting and ending points established, how do we bridge the two? Well, that’s the Data Professionals’ craft.
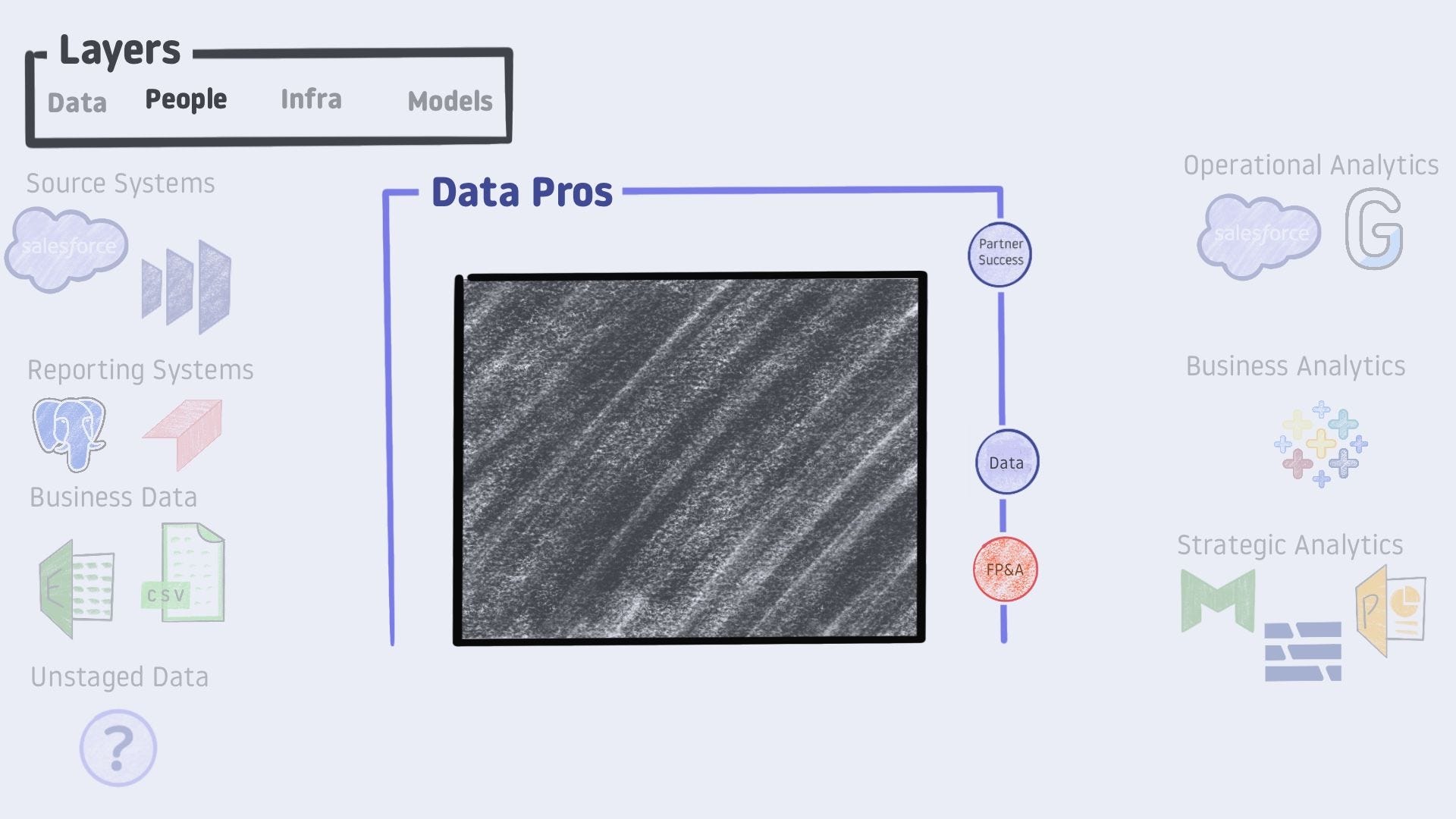
Data teams may look like an individual. They may be specialized - engineers, scientists, and analysts. They may be federated - with multiple professionals embedded in different functional areas but collaborating in a central location.
From the perspective of your colleagues, the data team always has a black box that turns data into models. Colleagues will see the data team as a black box whether the team is a solo analyst or federated across departments and specialized roles.
Within that black box are the analyst’s tools. The infrastructure needed to perform their craft.
Are you ready to take a look?
Infrastructure
Focus in on that black box.
It’s the most frequently debated part of delivering a data product.
Do you know what’s inside?
Any ideas?
Picture it in your mind.
Got it?
Let’s take a look...
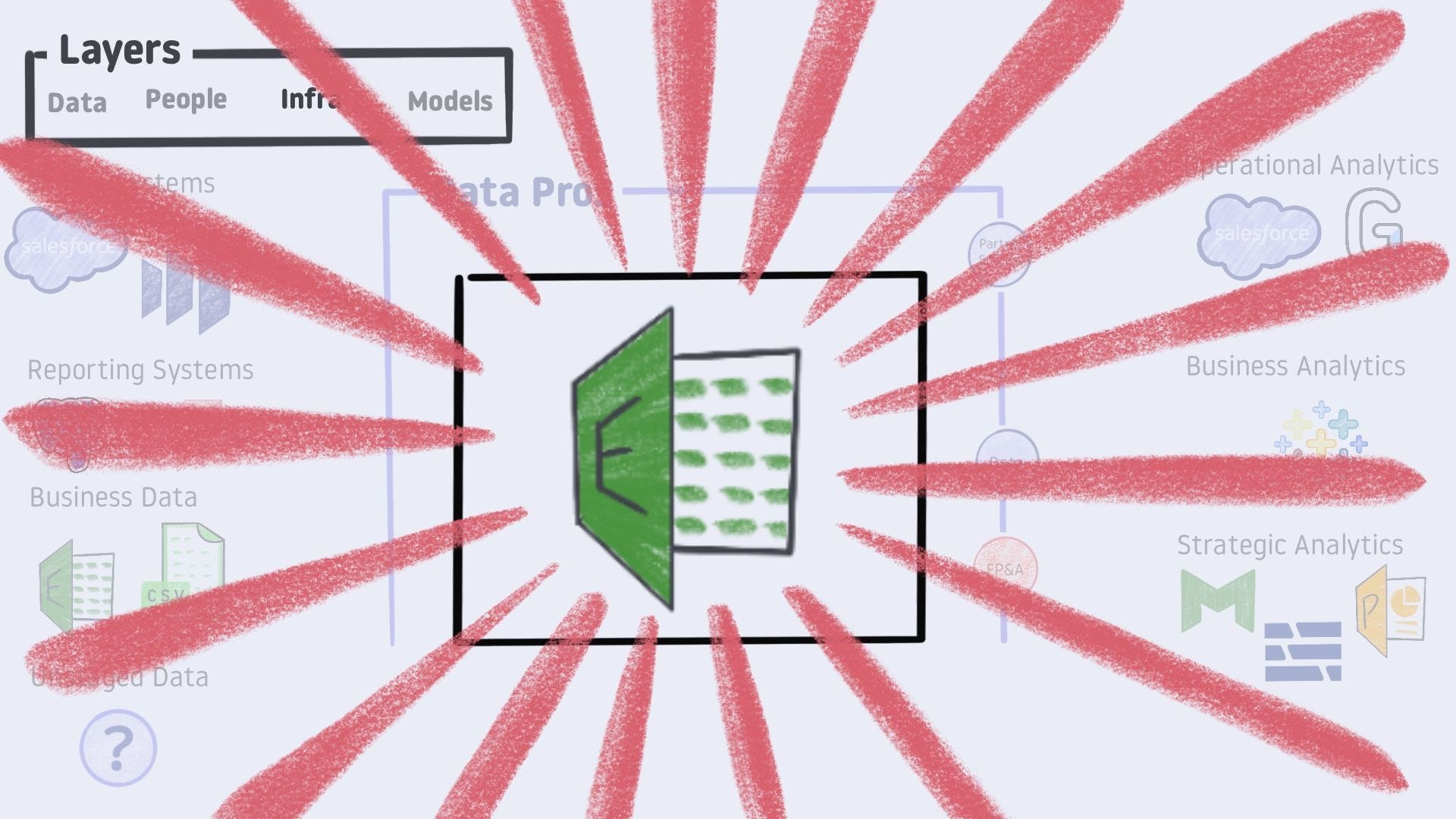
It’s Excel!!!
Of course it’s Excel!
I’m saying this a bit tongue in cheek - but it honestly is a valid answer for analytics infrastructure.
While Excel can be pushed into service when the need arises, it should not be your first choice. We are looking for better infrastructure.
The fact that it is possible to deploy multiple analytic infrastructures from various groups is worth its own aside.
Multi People / Infra Combo Aside
Let’s put the lid back on our main black box and acknowledge that other people in the company may provide modeled data. PMs might pull together their own Excel report to track feature adoption. A siloed data team in marketing will stand up their own tooling to follow ad campaign performance. These individuals always have good intentions for the company, but it can cause problems.
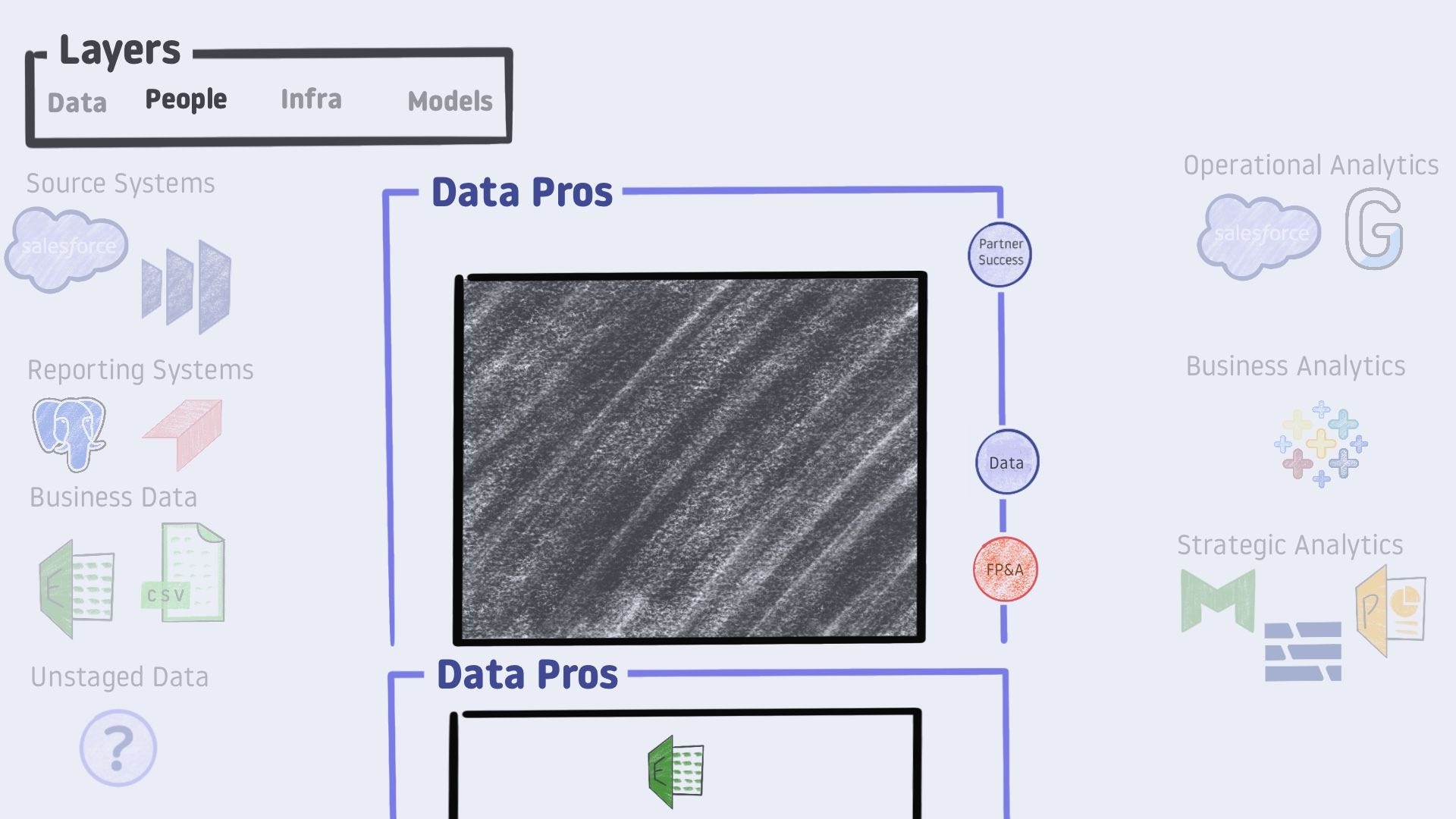
With multiple people involved and differing methodologies used to share numbers, it is just a matter of time before a contradiction occurs.
"Why don’t these numbers tie out?"
"That’s not the number I have."
"How are you defining Net Retention?"
These contradictions slow decision-making and erode trust. They are nearly impossible to prevent from arising. Since you cannot stop it, you need to plan for it.
A few quick ideas on how to handle fractured modeling processes:
An endorsement process to separate golden datasets from exploratory work
An onboarding process to get data-centric colleagues working on shared infrastructure
Data Mesh
With that in mind, it’s time to get back to the main show.
Infrastructure x2
Popping the lid back off, let’s take a closer look at a modern data stack deployment.
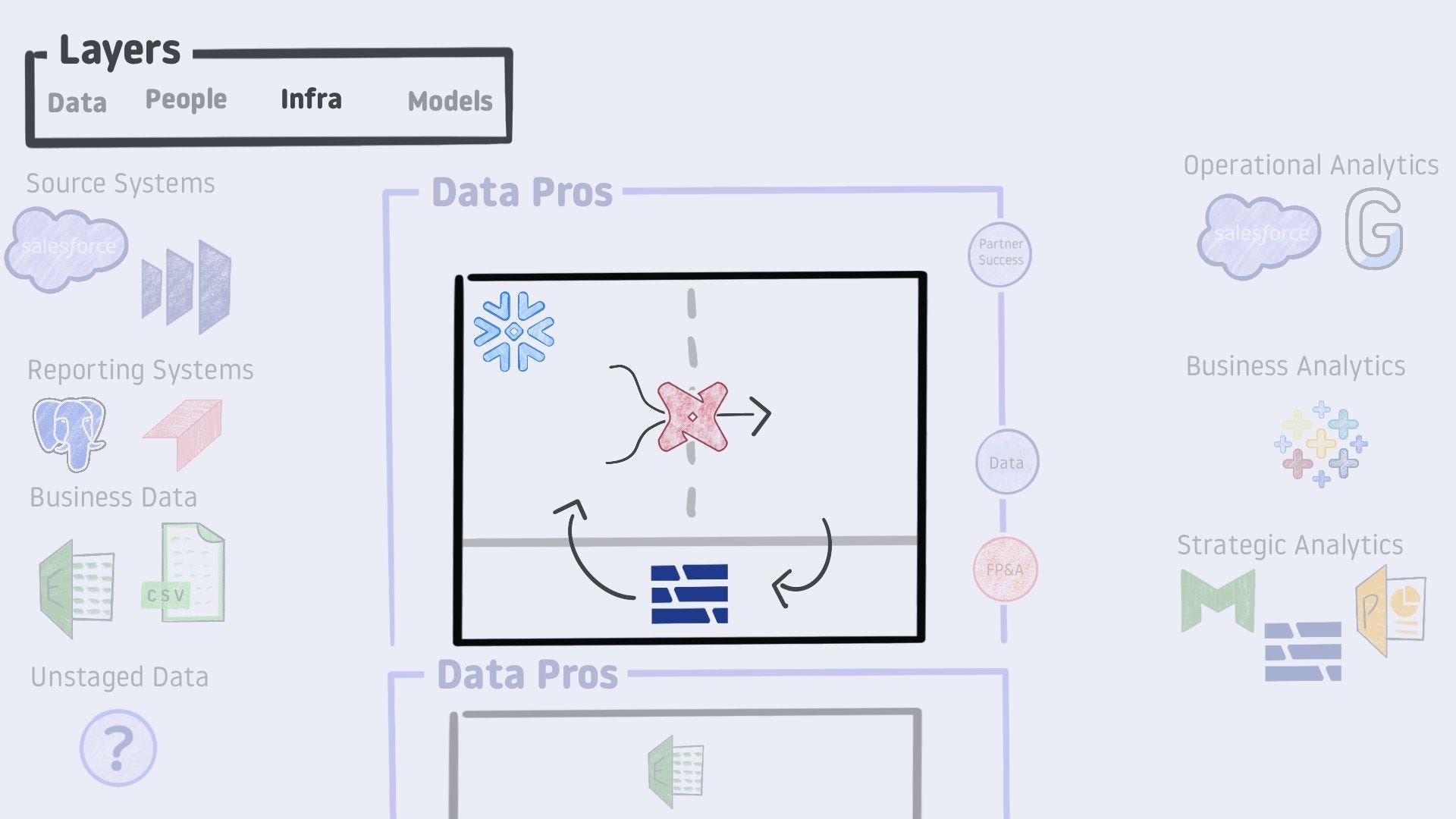
Snowflake serves as the workhorse behind the staging and analysis layers. dbt is responsible for transforming the staged data into something ready for use in our final models. Then Hex opens some exciting possibilities. While Hex lives outside of Snowflake, it can read from the transformed layer and write to the staged layer. This feedback loop enables powerful workflows - ranging from master data management to operational forecasting.
Zoom Out
Shoo. Still with me?
Let’s give ourselves a quick pause, step back, and take a look at all we’ve established.
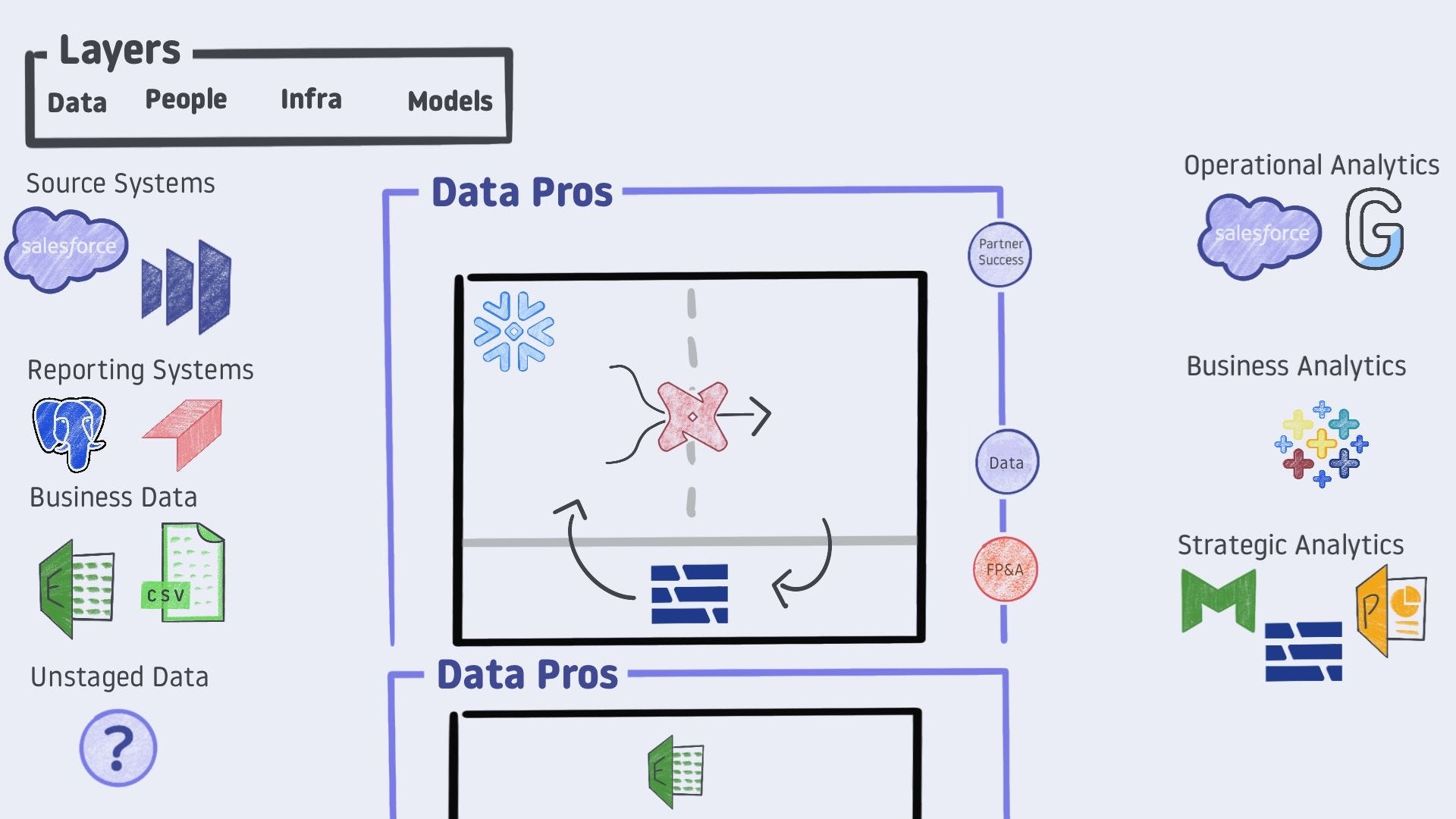
Looking at all four of our layers, we have
Data - our raw materials broken out into sub-categories, each with its own set of pros/cons and strategies
People - the individuals or teams responsible for managing the black box that delivers insight throughout the organization
Infra - the tooling that exists under the covers of the data professional’s black box
Models - the results an analytics team can deliver broken into sub-categories with an established purpose and challenges
There is no single correct answer for the people/infra combos. So come up with a plan to resolve contradictions that arise from differing approaches.
This framework still feels not quite complete. Keep going.
Integration
What we are still missing is a way to move from layer to layer. We need to wire up the machine.
Working in analytics has always been a tricky spot because of the need for domain knowledge and technical expertise. Following today’s nomenclature, Anna defines this idea as red ❤️, blue 💙, and purple 💜 people.
Red people have strong domain expertise
Blue people are technically focused
Purple people blend the two
Extending this convention, we can add hooks to each component of our framework.

The data and models layers have both business context and technical hooks.
Notice the unstaged data only has a red hook. Other individuals may be pulling from unknown sources. It is impossible to technically hook into an unstaged source until the data team does discovery work. From the discovery process, the team identifies the unstaged data as one of the other three data types.
The infrastructure layer has purple hooks. The technical component is clear, but much of an analysis’ value comes from encoding domain knowledge into the infrastructure.
Analytics professionals are generally purple people or at least purple teams. Multiple teams may plug into a single toolset but may have varying technical and domain knowledge levels. For example, the FP&A team is a red node - strong business understanding but not fully equipped to handle technical work tracing back to the source systems.
Technical Wiring
Connecting everything technically is honestly one of the more manageable pieces of the whole framework. That’s not to say the decisions made here are without consequence. Depending on the integration tooling you choose, you can enable/disable loading of specific data sources or delivery of an entire category of models. Whether you build or buy determines how much time the team will spend maintaining the integrations.
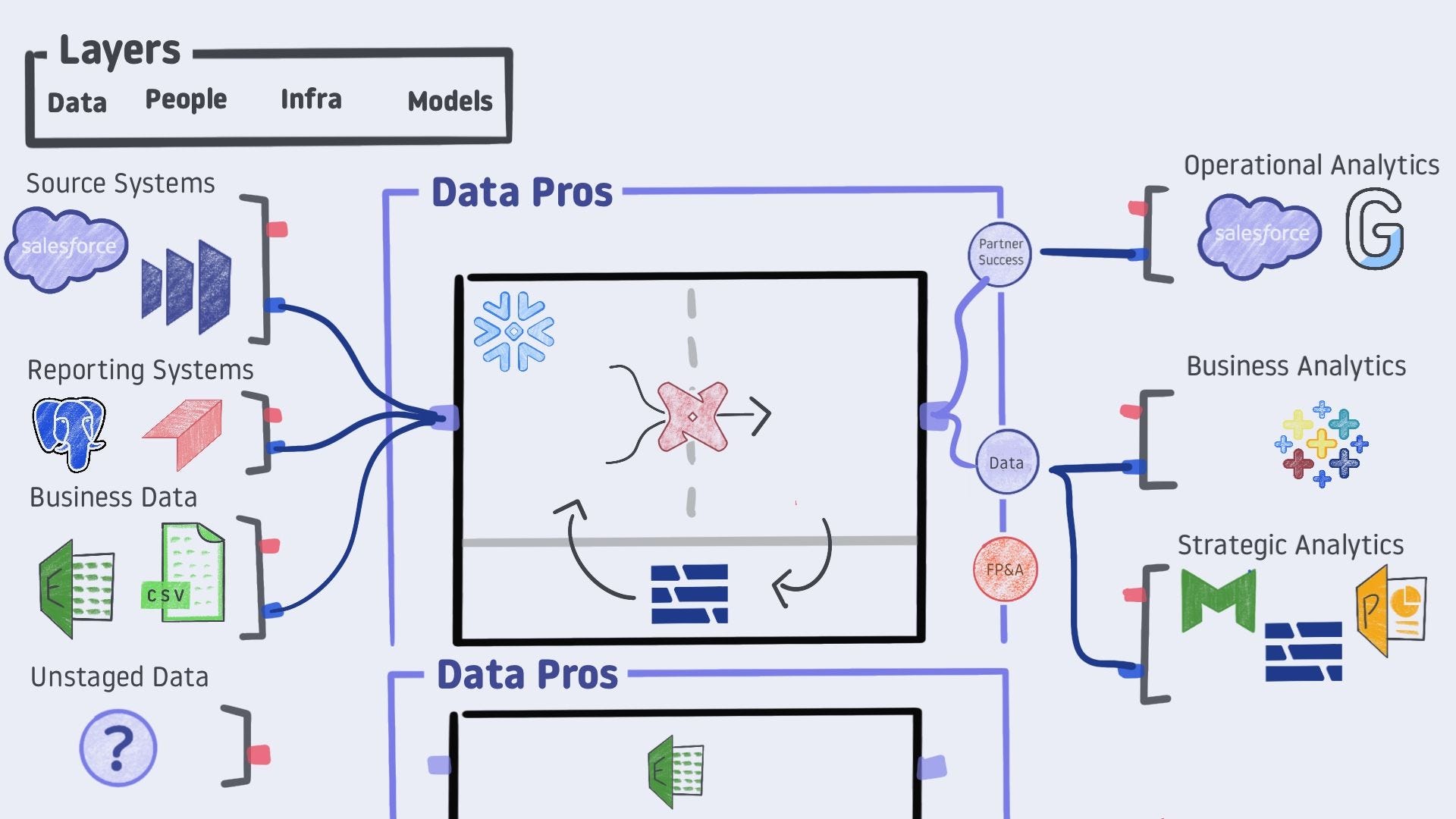
Domain Wiring
No tooling to the rescue here. It is hard work, and you’ll need to find what works for your organization. Here are some rapid-fire ideas to kickstart your ideation:
Writing down your understanding and reviewing it with business leaders to fill in gaps
Creating a sample data model with dummy data before writing any code
Contributing to a corporate wiki
Whiteboarding or doodling
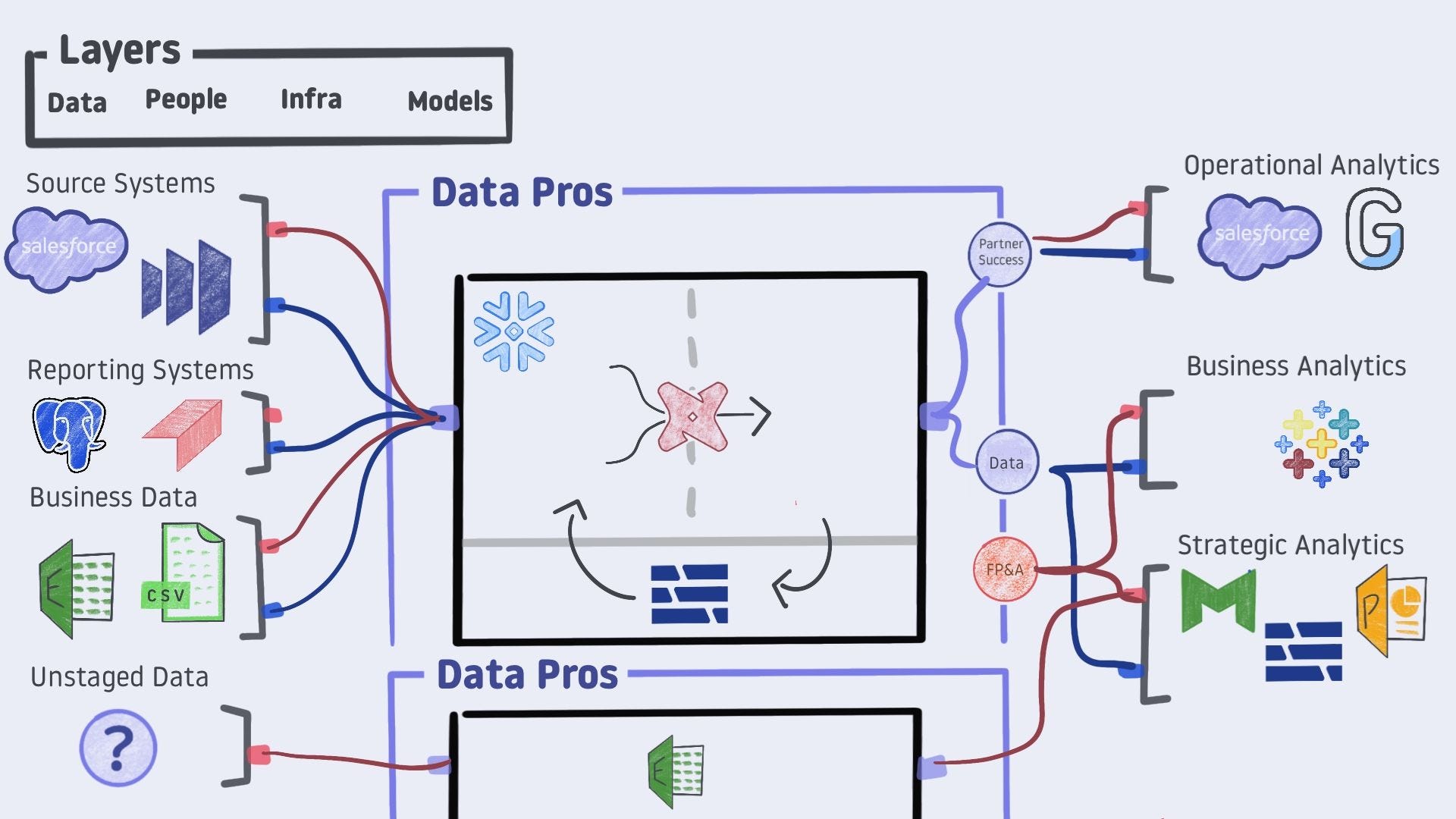
A couple of gotchas to call out here.
One, the reporting systems do not have their domain knowledge wired up. The data team could try to assume the business context - but you know what they say about assuming.
Two, the fractured people/infra combos are both feeding strategic analyses. Fractured workflows run up the risk of conflicting information and could ultimately hurt the organization’s decision-making. Watch out for this.
We have come a long way. Time to bundle it all up.
Bundling it up
All the pieces are on the board. Data is captured and fed to data professionals via ETL/ELT tools. That data is contextualized with domain knowledge from the business. Those pros then leverage their infrastructure to shape data and encode understanding into an analytic asset. That asset is shared as a model to inform decisions throughout the organization.
Even conceptually knowing all the pieces, in practice everyone’s situation will look different. It is ok to say operational analytics is out of the question today due to data quality at a granular level. It’s ok to acknowledge a need to deepen domain understanding before taking on a strategic analysis. It is alright to admit decisions are slowed from conflicting data points between different teams models. Understanding your situation will empower you to see how to make it better. I hope this framework can help you in that journey.
Bonus
If you want to apply this framework to your situation, here are a couple bonus helpers.
Save a copy of the blank DPIM Framework doodle to draw on
{kind=link}
- or -
Duplicate this Google Sheet template to fill in your details